Here be dragons!
The greatest challenges to adopting Agile at scale are organisational. Therefore any scaled implementation needs careful attention to communication, culture and change management. As CIO and agile consultant Marius de Beer observes: “When you scale, you scale everything. The good and the bad.” I suggest that you accept that there is no “silver bullet” solution to doing Scrum (or any form of Agile) at scale. With this mindset I suggest you read broadly what others have done and are doing. I especially recommend the Larman and Vodde books as well as Henrik Kniberg’s papers and presentations.
If you are a novice and are serious about helping your organisation get better, find and hire an Agile coach who has a verifiable pedigree in applying Agile at the scale you need. This will shorten your learning curve and lessen the pain!
Lastly, be prepared for a multi-year journey towards organisational agility. Whilst I have seen tremendous improvements within just a few months, serious “sticky” change, especially at scale, will take a long time: think five to ten years. The good news is that it can be a lot of fun with rewards all along the way.
Conway’s Law
Conway’s Law states:
“Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.” [Conway 1968]
Conway’s Law is never more evident than in distributed teams and organisations. Teams that are not collocated experience the greatest communication challenges by definition. How teams and their communication is structured has a major impact on how well they design and execute their products. I encourage managers to defer to their team members in designing effective structures!
Some scaling techniques
The following sections will give you a short overview of a few scaling approaches and my opinion of each.
Multi-team sprinting
Henrik Kniberg has led this approach [Kniberg 2008]. The main idea is to create a single, unified Product Backlog, form multiple Scrum-sized teams and run synchronised Sprints with a joint Sprint Goal. This means Sprint Planning and Reviews are done jointly by all teams together. Daily Scrums are done team by team. These are complemented by some means of inter-team synchronisation, often a Scrum of Scrums. Retrospectives can be done jointly, team by team or in other affinity groupings. I vary this to achieve cross-learning. Facilitation of large meetings requires good skills. I use large-group techniques and multiple facilitators.
My opinion: I have applied this pattern in many organisational units with 12 to 50+ team members working on single and multiple products, with one or multiple customers. The results have exceeded my own and my clients’ expectations.
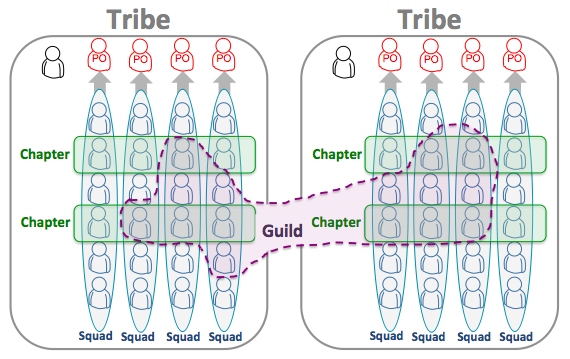
The Spotify journey
Henrik Kniberg and Anders Ivarsson have published an interesting paper on scaling at Spotify [Kniberg & Ivarsson 2012]. These authors all have deep experience in doing Agile at scale and have extracted the essence of what works (and what does not) into useful principles and patterns.
The figure shows a snapshot of Spotify’s organisational design and language.
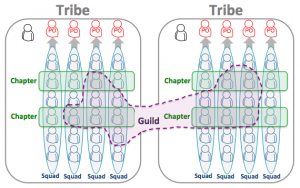
My opinion: The Spotify story is inspirational to many practitioners (including me) who are trying hard to build agile organisations. It is a fountain of good ideas and thinking. It is not a recipe you can apply to your situation.
SAFe
At the other end of the scale Dean Leffingwell has developed the SAFe model for Agile at scale [Leffingwell 2012]. The model contains concepts that some may find useful, such as the Release Train, but also contains a lot of “process voodoo” that will not be required in most cases.
Sophisticated models such as SAFe approach the scaling problem from the perspective of providing a menu of all the possible constructs that might be needed in any conceivable scenario. The result is a confusingly complicated framework that requires an expert process practitioner (or coach) to optimise it for your specific needs. Anyone with experience of the Rational Unified Process (RUP) will recognise this.
Moreover, SAFe attempts to codify what is inherently a complex problem requiring unique and nuanced solutions that will be different for every environment. Critics will recognise this as an attempt to describe simple/complicated solutions for complex problems (see our earlier article on the Cynefin framework for an understanding of complexity). On the other hand supporters claim that SAFe enables them to begin conversations with conservative PMO managers who were previously unwilling to discuss Agile methods.
My opinion: SAFe offers an appealing diagram for those who still believe that problems of project management are solvable by applying sufficient process and governance. I think SAFe heightens the risk of just applying “lipstick to the pig” and not dealing with the fundamental changes that are required in every organisation I have worked with.
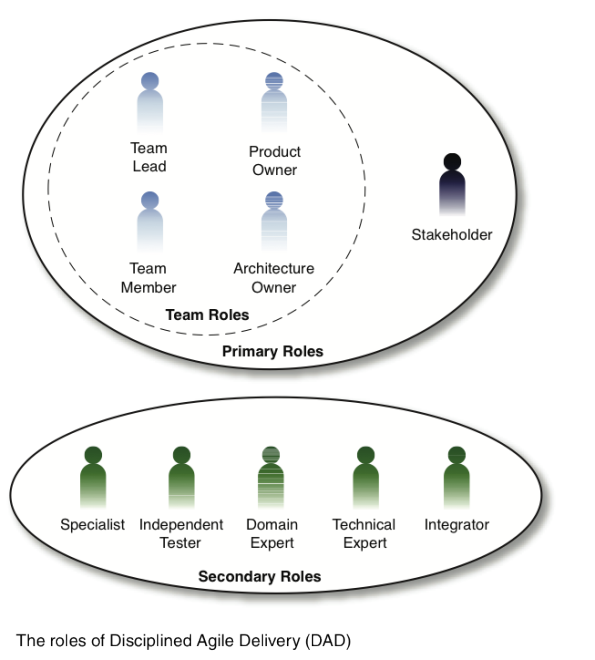
DAD
The formal definition of DAD from its authors is: “The Disciplined Agile Delivery (DAD) decision process framework is a people-first, learning-oriented hybrid agile approach to IT solution delivery. It has a risk-value delivery lifecycle, is goal-driven, is enterprise aware, and is scalable.” [Ambler and Lines 2012]
DAD describes a “full agile delivery lifecycle” as comprising three phases: Inception, Construction and Transition. This is derived from the RUP. The DAD description goes on to describe three lifecycle variants: the “Agile/Basic DAD Lifecycle: Extending Scrum”, the “Advanced/Lean DAD Lifecycle” and the “Continuous Delivery DAD Lifecycle”. DAD’s authors appear to have repackaged Scrum and elements of Kanban.
DAD also adds more roles, both within the team (notably an Architect role), defining five primary and five secondary roles, as shown in the figure reproduced from the DAD web site.
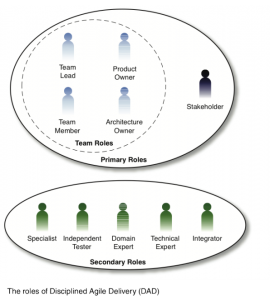
My opinion: Scott Ambler has many useful things to say about Agile methods and practices. Nevertheless I find the DAD description less practical and helpful than starting with either Scrum or Kanban and iterating towards a better set of processes for your teams and organisation.
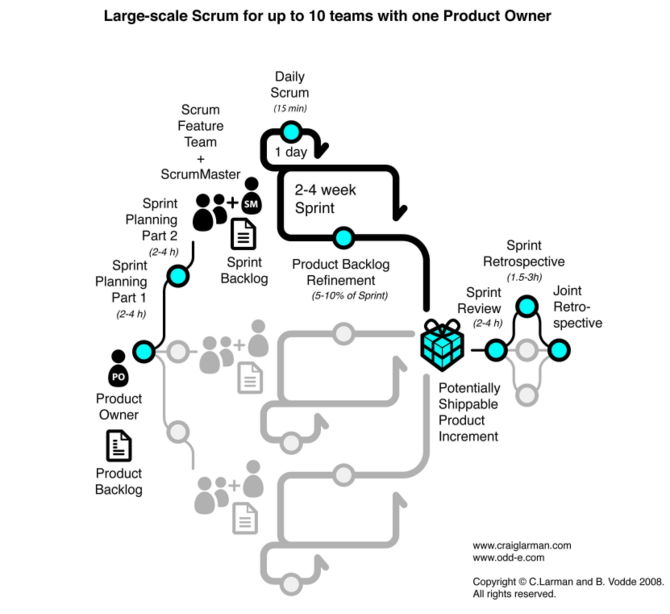
LeSS
Craig Larman and Bas Vodde have both been working with Agile methods at larger scale and for longer than most other practitioners. They have resisted the temptation to derive a one-size-fits-all set of practices. What they have done is to document tools and practices that they have applied in different situations as a guide to what you might try and what you might wish to avoid.
The output of their work is named LeSS, an initialism for “Large Scale Scrum”. These have been documented comprehensively in two books: “Scaling Lean & Agile Development: Thinking and Organizational Tools for Large-Scale Scrum” [Larman and Vodde 2008] and “Practices for Scaling Lean & Agile Development: Large, Multisite, and Offshore Product Development with Large-Scale Scrum” [Larman and Vodde 2010].
The figure below shows the LeSS model for scaling up to ten teams or 100 people. LeSS contains a corresponding model for scaling to hundreds of teams and thousands of people.
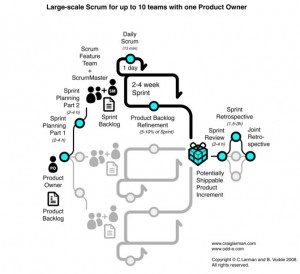
Larman’s Laws of Organisational Behaviour
Larman warns that organisational change is hard and that it is best to start with changing structure. He states the following “laws” from his observation of organisations over decades [Larman 2013]:
-
- Organisations are implicitly optimised to avoid changing the status quo: middle- and first-level manager and “specialist” positions & power structures
-
- As a corollary to (1), any change initiative will be reduced to redefining or overloading the new terminology to mean basically the same as status quo
-
- As a corollary to (1), any significant change initiative will be derided as “purist”, “theoretical”, and “needing customisation for local concerns”—which deflects from addressing weaknesses and manager/specialist status quo
-
- Culture follows structure, i.e. if you want to really change culture, you have to start with changing structure, because culture does not really change otherwise. That’s why deep systems of thought such as organizational learning are not very sticky or impactful by themselves, and why systems such as Scrum (that have a strong focus on structural change at the start) tend to more quickly impact culture.
Ouch! The truth hurts.
My opinion: I like Larman and Vodde’s approach to this topic. I suggest you study their books carefully and try some experiments. Watch for more from them.
My own scaling approach
A helpful aphorism to bear in mind is “scale principles not practices”.
I offer below some principles and related practices I have drawn from Don Reinertsen’s Principles of Product Development Flow [Reinertsen 2009], from Larman and Vodde’s books, from conversations with other agile coaches, and from my own experiences with applying Scrum at scale with my own consulting clients during the past eight years. Understand that this is only scratching the surface of what it means to apply Agile at scale.
Scrum Scaling Principles & Practices
Minimise cross-dependency between teams, so
Form feature teams rather than component teams, and
Ensure each team is cross-functional.
Stick to the “right” team size, no matter what, so
Merge multiple products into one backlog feeding a single team, or
Let a single backlog feed multiple teams.
Reduce skill silos and dependencies within teams, so
Grow T-shaped people
Employ small batches to reduce cycle time, reduce variability and increase efficiency, so
Avoid large work items in Sprints, and
Use a regular cadence for all Sprint meetings.
Shorten queuing times for the waiting work, so
Feed multiple, synchronised teams from a single backlog.
Exploit scale economies of multiple teams, so
Synchronise sprints for multiple teams.
Retain slack to achieve flow, so
Allow teams to pull from the backlog, based on their observed capacity, and
Challenge teams to finish early as least as often as they finish late.
Keep feedback loops short, so
Ensure all teams’ outputs are tested and integrated into the Increment every Sprint, and
Work to eliminate constructs like “integration” or “hardening” sprints.
Optimise the whole, so
Measure outcomes at the highest possible level, and
Let teams seek on their own local solutions.
Pay attention to quality, so
Ensure “technical debt” is reducing, not increasing, and
Fix errors as soon as they are found.
Pay attention to communication, so
Institute formal meetings to synchronise teams.
Pay attention to learning, so
Form communities of practice for different disciplines to share learning, and
Hold large group retrospectives on a longer cadence (e.g. for releases).
References
Ambler, Scott M. and Lines, Mark (2012). Disciplined Agile Delivery: A Practitioners’ Guide to Agile Software Delivery in the Enterprise. IBM Press.
Kniberg, Henrik (2008). Multi-Team Sprint Planning. http://www.scrumalliance.org/system/resource_files/0000/0871/Multi-Team-Sprint-Planning.pdf.
Kniberg, Henrik and Ivarsson, Anders (2012). Scaling Agile @ Spotify with Tribes, Squads, Chapters & Guilds. http://blog.crisp.se/2012/11/14/henrikkniberg/scaling-agile-at-spotify.
Larman, Craig and Vodde, Bas (2008). Scaling Lean & Agile Development: Thinking and Organizational Tools for Large-Scale Scrum. Addison-Wesley Professional.
Larman, Craig and Vodde, Bas (2010). Practices for Scaling Lean & Agile Development: Large, Multisite, and Offshore Product Development with Large-Scale Scrum. Addison-Wesley Professional.
Larman, Craig (2013). Larman’s Laws of Organizational Behavior. http://www.craiglarman.com/wiki/index.php?title=Larman’s_Laws_of_Organizational_Behavior
Leffingwell, Dean (2013). Scaled Agile Framework. http://scaledagileframework.com/.
Reinertsen, Donald G. (2009). The Principles of Product Development Flow: Second Generation Lean Product Development. Celeritas Publishing.








'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Your Privacy Choices
Your Privacy Choices{kind=link}